Turn Documents Into Usable Knowledge
Bulkgrid converts documents into structured, searchable knowledge, making PDFs and files as easy to use as web content in your AI systems.
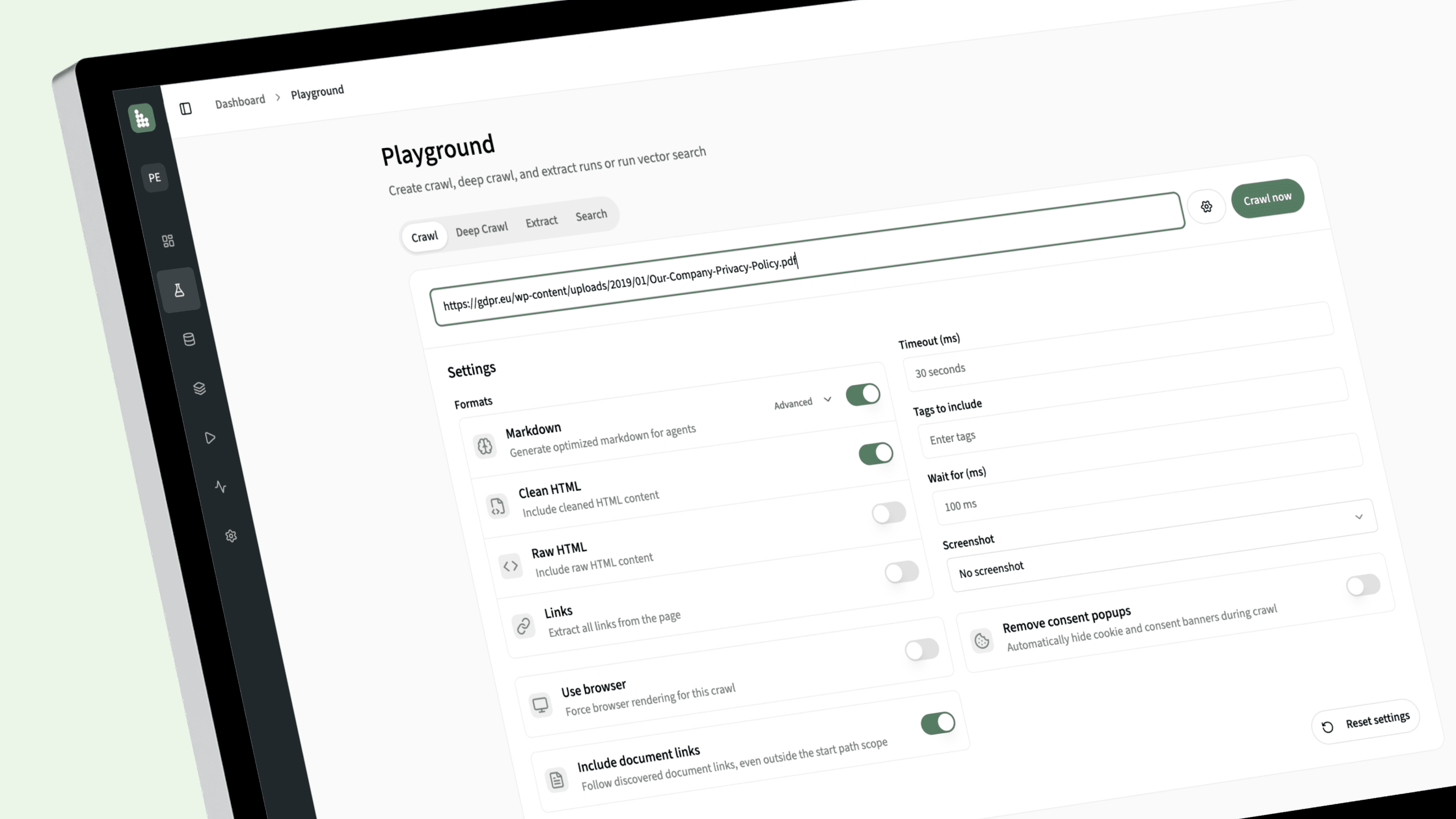
Document Ingestion Features
Turn raw documents into reliable AI-ready knowledge with format-aware parsing, OCR, structured extraction, metadata capture, incremental updates, and resilient processing at scale.
Multi-Format Parsing
Ingest PDFs, DOCX, PPTX, XLSX, TXT, HTML, and other common document formats into a consistent structured pipeline.
OCR for Scanned Files
Extract text from scanned or image-based documents so non-searchable files still become usable knowledge.
Layout-Aware Extraction
Preserve headings, tables, lists, and section boundaries to keep document meaning and context intact.
Metadata Capture
Index author, title, created/modified timestamps, source path, and custom tags for governance and filtering.
Deduplication and Versioning
Detect duplicate files and track document revisions to avoid index bloat and maintain a clear content history.
Incremental Reprocessing
Reprocess only changed files and pages, reducing compute cost while keeping indexed content current.
Semantic Chunking
Split documents into retrieval-ready chunks with context preserved, improving relevance for search and RAG.
Access-Controlled Ingestion
Respect source permissions and scope content by team or collection so only authorized data is indexed and retrievable.
Reliable Processing Pipeline
Use queues, retries, and idempotent jobs to process large document volumes reliably under failures and spikes.
Turn Every Document Into Trusted, Searchable AI Knowledge.
Start Indexing Documents Your AI Can Actually Use
Create your account and turn PDFs, docs, and files into structured, searchable knowledge in minutes with automatic refresh and reliable retrieval.
Get Started